iSpLib: An Auto-tuned GNN Accelerator for PyTorch
iSpLib: A Library for Accelerating Graph Neural Networks using Auto-tuned Sparse Operations
The iSpLib project originated from FusedMM, the first initiative I undertook upon joining the Luddy HipGraph Lab in 2022 under Dr. Ariful Azad’s supervision. The lab focuses on developing high-performance sparse kernels for efficient graph computations by mapping graph operations to equivalent linear algebraic functions. FusedMM, developed by two lab researchers in 2021, is a sparse matrix multiplication library that detects system OS flags and supported SIMD (Single Instruction, Multiple Data) instructions to generate optimized BLAS-like kernels—such as sparse-dense matrix multiplication (SpMM) and sampled dense-dense matrix multiplication (SDDMM)—tailored to the host architecture. These kernels deliver comparable performance across Intel, AMD, and ARM processors.
My primary contribution was creating a PyTorch front-end for FusedMM to enable seamless integration with standard Graph Neural Network (GNN) training pipelines. To achieve this, I implemented the following enhancements:
Dynamic Library Generation: I adapted the FusedMM codebase to produce a dynamic library, linking PyTorch tensor arrays to FusedMM’s low-level C interface. Originally, FusedMM generated a static library bundling all configuration-specific C code. For Python interoperability, I modified the build system to include the
-fPICflag, enabling position-independent code.Backpropagation Support for Semirings: I extended FusedMM’s SpMM functionality to return both the reduced value and its index for “min” and “max” operations, which is essential for backpropagation in these semirings. This extension supports diverse aggregation mechanisms (e.g., min, max, mean) required for algorithms like GraphSAGE.
Caching for Backpropagation: During implementation, I observed that gradients are repeatedly multiplied by the transposed sparse matrix (typically the fixed adjacency matrix in static graphs) across epochs, incurring redundant costs from expensive CSR-to-CSC conversions. I introduced a caching mechanism using a hashtable keyed on tensor pointers to store the transpose, avoiding recomputation and enabling conflict-free handling of multiple sparse matrices in a single session.
These optimizations, combined with FusedMM’s generated kernels, yielded up to 93× speedup over vanilla PyTorch 2.1 GCN implementations on large datasets like Reddit and OGBN-Proteins. Released as the Intelligent Sparse Kernel Library (iSpLib), it delivered the following speedups relative to PyTorch Geometric 2.4 for two-layer GNNs:
| Model | Speedup |
|---|---|
| GCN | 54× |
| GraphSAGE-SUM | 32× |
| GraphSAGE-MEAN | 23× |
| GIN | 51× |
Inspired by the plug-and-play ethos of our funding agency (ICICLE), I developed a simple two-line patching interface for integrating iSpLib into existing PyTorch Geometric GNN codebases. Patching can be reversed via iSpLibPlugin.unpatch_pyg() at any time. Additionally, a @isplib_autotune decorator allows targeted patching of specific PyG functions.
from isplib import *
iSpLibPlugin.patch_pyg()
# Your PyTorch Geometric code hereAuto-Tuner Interface
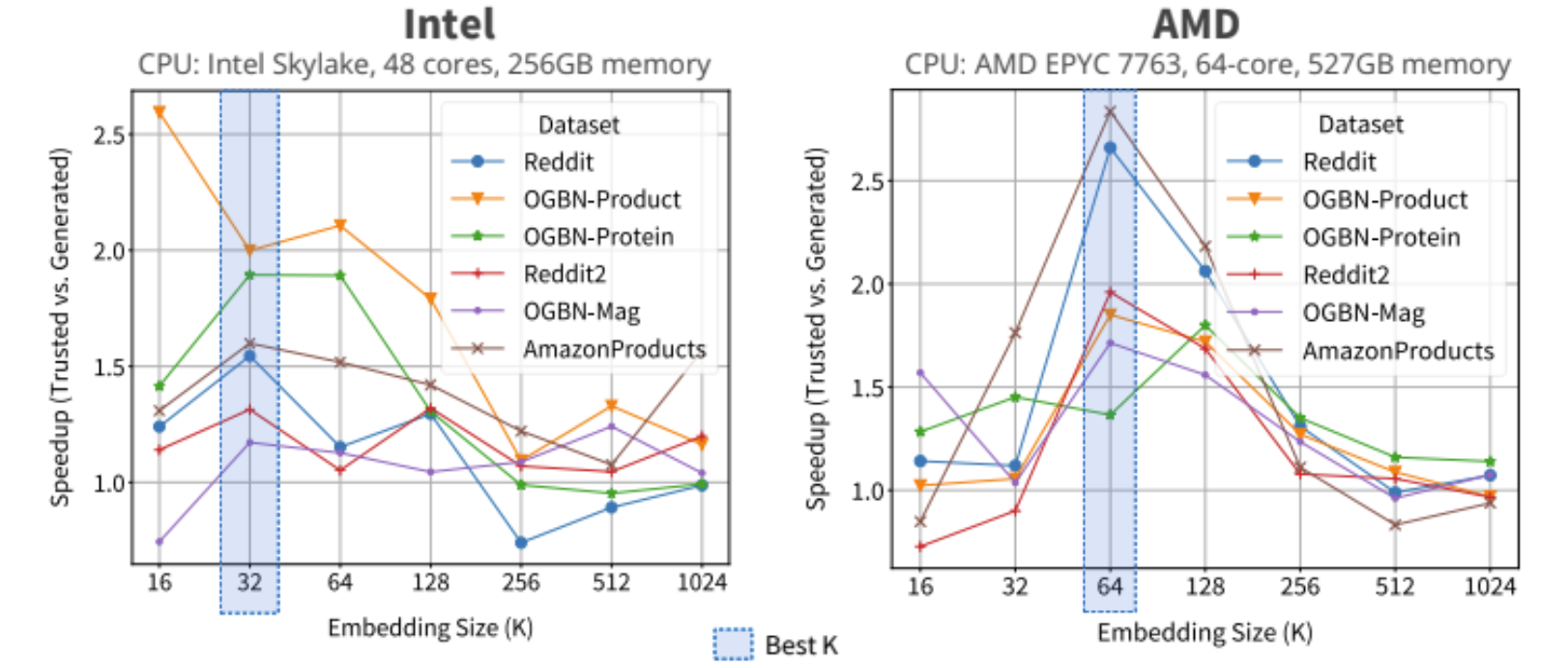
I also built a Python interface for FusedMM’s auto-tuner, compatible with graph datasets in MTX format. The auto-tuner includes fallback kernels for robustness. By benchmarking generated kernels against fallbacks across embedding sizes, we generate speedup curves—typically parabolic, peaking at the optimal embedding dimension before register spilling degrades performance. For most datasets, iSpLib peaks at embedding size 32 on Intel CPUs and 64 on AMD CPUs (e.g., on NERSC supercomputers), largely due to AMD’s larger cache.
Acknowledgments and Impact
I extend my deepest gratitude to Dr. Ariful Azad for his unwavering guidance and to Pranav Badhe for his invaluable assistance in experiments, AMD benchmarking, and paper feedback. The project spanned 18 months, culminating in publication at ACM WebConf 2024.
Through iSpLib, I gained expertise in high-performance computing (HPC) techniques, including auto-tuning, code generation, loop unrolling, OpenMP primitives, and SIMD vectorization. This experience has motivated further explorations in graph ML optimizations, such as efficient sparse training for knowledge graphs.
#PyTorch #PyG #Backpropagation #AutoTuning #BLAS #GCN #GIN #GraphSAGE #Semiring #ML #GNN #HPC