SIMD Intrinsics in Practice: Measuring Scalar vs SSE2 vs AVX2 Performance
Hands-on
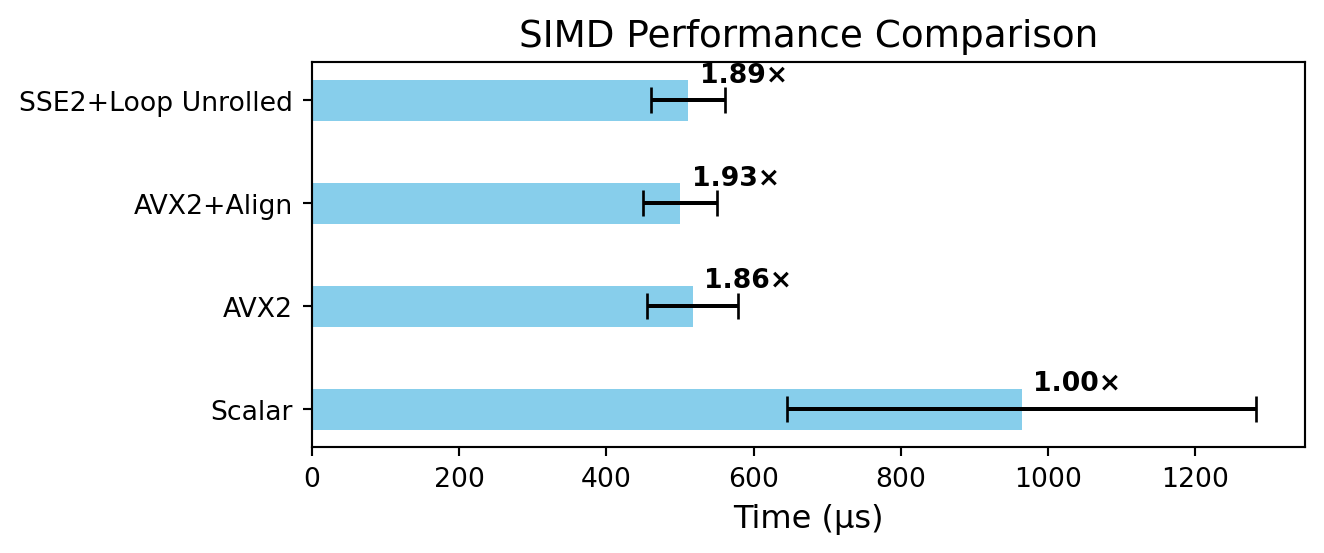
A simple 8-element vector add benchmark shows that AVX2 with proper alignment is fastest, followed by SSE2, unaligned AVX2, and finally scalar code.
I ran a small benchmark to demonstrate the use of various SIMD intrinsics and to compare their performance. The test measured the speedup of a simple 8-element vector addition implemented in four ways: scalar code, SSE2 intrinsics, AVX2 intrinsics, and AVX2 with explicit alignas memory alignment.
The results showed a clear performance hierarchy. The AVX2 implementation with aligned data performed best, followed by SSE2, then unaligned AVX2, with the scalar version being the slowest. This highlights how both wider vector units and proper data alignment can have a measurable impact on SIMD performance, even for small workloads.
Unaligned AVX2 can be slower than SSE2 because the overhead of wider 256-bit operations outweighs their benefits for very small workloads. Unaligned AVX2 loads may require extra micro-operations or split memory accesses, and on many CPUs they can also trigger a lower core frequency when AVX instructions are used. For an 8-element vector add, these costs dominate, while SSE2 avoids AVX downclocking and moves less data per instruction, making it more efficient in this case. Once data is properly aligned or the workload grows, AVX2’s wider vectors regain their advantage.
Scalar
#include <stdio.h>
int main() {
float a[8] = {1, 2, 3, 4, 5, 6, 7, 8};
float b[8] = {10, 20, 30, 40, 50, 60, 70, 80};
float result[8];
// Plain old scalar addition - one element at a time
for (int i = 0; i < 8; i++) {
result[i] = a[i] + b[i];
}
return 0;
}Run and Profile
gcc -O3 0_scalar_add.c
perf stat -r 5 -- ./a.outTime taken: \(0.000964 \pm 0.000319\) seconds
AVX2 Intrinsics
#include <immintrin.h> // AVX2 intrinsics
#include <stdio.h>
int main() {
// Two input arrays of 8 floats each
float a[8] = {1, 2, 3, 4, 5, 6, 7, 8};
float b[8] = {10, 20, 30, 40, 50, 60, 70, 80};
float result[8];
// Load into 256-bit SIMD registers (ymm)
__m256 va = _mm256_loadu_ps(a);
__m256 vb = _mm256_loadu_ps(b);
// Add them in one SIMD instruction
__m256 vresult = _mm256_add_ps(va, vb);
// Store result back to memory
_mm256_storeu_ps(result, vresult);
return 0;
}Run and Profile
gcc -O3 -mavx2 1_vector_add.c
perf stat -r 5 -- ./a.outTime taken: \(0.0005174 \pm 0.0000617\) seconds
AVX2 Intrinsics + Align
#include <immintrin.h>
#include <stdio.h>
#include <stdalign.h>
int main() {
alignas(32) float a[8] = {1,2,3,4,5,6,7,9};
alignas(32) float b[8] = {10,20,30,40,50,60,70,90};
alignas(32) float result[8];
_mm256_store_ps(result, _mm256_add_ps(
_mm256_load_ps(a),
_mm256_load_ps(b)
));
return 0;
}Run and Profile
gcc -O3 -mavx2 2_vector_add.c
perf stat -r 5 -- ./a.outTime taken: \(0.0004999 \pm 0.0000505\) seconds
SSE2 Intrinsics
#include <emmintrin.h> // SSE2
#include <stdio.h>
int main() {
float a[8] = {1, 2, 3, 4, 5, 6, 7, 8};
float b[8] = {10,20,30,40,50,60,70,80};
float result[8];
// First half (elements 0–3)
_mm_storeu_ps(result + 0,
_mm_add_ps(
_mm_loadu_ps(a + 0),
_mm_loadu_ps(b + 0)
));
// Second half (elements 4–7)
_mm_storeu_ps(result + 4,
_mm_add_ps(
_mm_loadu_ps(a + 4),
_mm_loadu_ps(b + 4)
));
return 0;
}Run and Profile
gcc -O3 -msse2 3_vector_add.c
perf stat -r 5 -- ./a.outTime taken: \(0.0005111 \pm 0.0000500\) seconds
Summary
The following table summarizes the execution time of various implementations—AVX2, SSE2, aligned AVX2, and scalar—and reports their corresponding speedups relative to the scalar baseline. All experiments were conducted on an Intel® Core™ Ultra 9 Processor 285H with 24 MB cache and a maximum turbo frequency of 5.40 GHz.
| Method | Time (µs) | Speedup |
|---|---|---|
| Scalar | \(964.0 \pm 319\) | \(1\times\) |
| AVX2 | \(517.4 \pm 61.7\) | \(1.863\times\) |
| AVX2+Align | \(499.9 \pm 50.5\) | \(1.928\times\) |
| SSE2+Loop Unrolled | \(511.1 \pm 50.0\) | \(1.886\times\) |