Getting Started with TinyCUDA
📌 GitHub Link: https://github.com/OnixHoque/tinyCUDA.
🌟 Please leave a star if you like it!
Why TinyCUDA?
CUDA lets you speed up heavy computations on your GPU, but it often means dealing with a lot of setup code for things like memory copies, error checks, and timing. TinyCUDA is a simple, header-only C++17 library that handles this boilerplate (memory management, profiling, error checking) for you. It lets you focus on writing your kernels, making it great for quick prototypes or learning.
What You Need
- CUDA Toolkit 11.0+ with
nvcc. - A C++17 compiler.
- An NVIDIA GPU.
Setup
No building required—it’s just headers!
Grab the repo:
git clone https://github.com/OnixHoque/tinyCUDA.gitAdd
include/tinycuda/to your project’s includes (like in athird_party/folder).In your
.cufile:#include "tinycuda/tinycuda.hpp" // Gets everything // Or pick what you need: // #include "tinycuda/memory.hpp" // #include "tinycuda/profiler.hpp" // #include "tinycuda/error.hpp"Build with
nvcc:nvcc -std=c++17 -I/path/to/tinycuda/include your_file.cu -o your_output
Test it out with the repo’s scripts:
cd tinyCUDA
./scripts/build_and_run.sh # Tries the vector add example
./scripts/run_tests.sh # Runs the testsQuick Examples
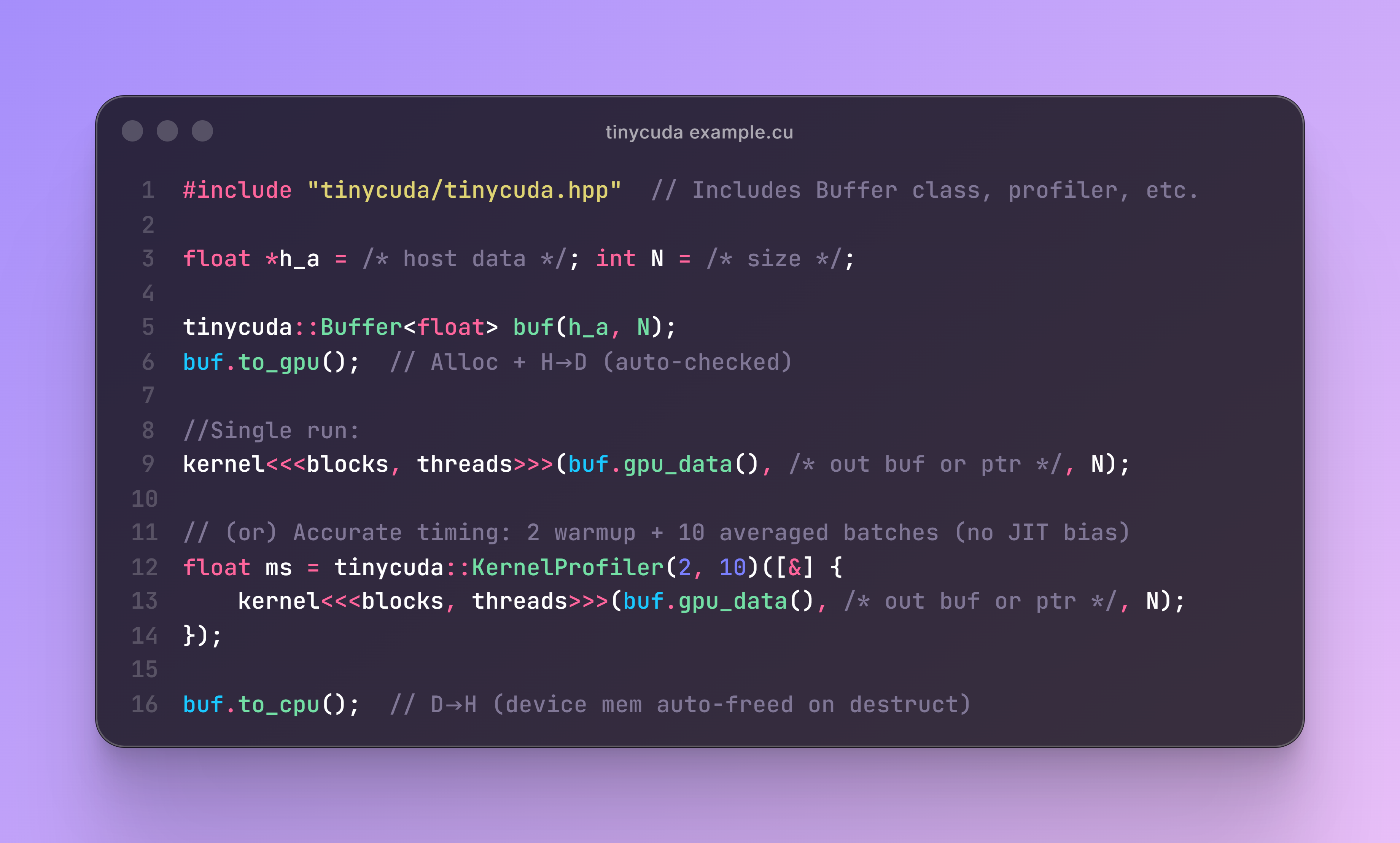
TinyCUDA has three main helpers: Buffer for memory stuff, KernelProfiler for timing kernels, and CUDA_CHECK for catching errors. We use this simple vector addition kernel across all examples: c[i] = a[i] + b[i] for N elements.
__global__ void vector_add(const float* a, const float* b, float* c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = a[idx] + b[idx];
}
}Handling Memory with Buffer
Buffer makes a GPU copy of your host data—easy allocation, copies, and cleanup. Full vector add.
#include "tinycuda/tinycuda.hpp"
#include <vector>
#include <cstdio>
#include <cmath>
int main() {
const int N = 1024;
const int threads = 256;
const int blocks = (N + threads - 1) / threads;
std::vector<float> h_a(N, 1.0f), h_b(N, 2.0f), h_out(N, 0.0f);
tinycuda::Buffer<float> buf_a(h_a.data(), N);
tinycuda::Buffer<float> buf_b(h_b.data(), N);
tinycuda::Buffer<float> buf_out(h_out.data(), N);
buf_a.to_gpu(); buf_b.to_gpu(); buf_out.to_gpu();
vector_add<<<blocks, threads>>>(buf_a.gpu_data(), buf_b.gpu_data(), buf_out.gpu_data(), N);
buf_out.to_cpu();
// Quick check
bool passed = true;
for (int i = 0; i < N; ++i) {
if (std::abs(h_out[i] - 3.0f) > 1e-5f) { passed = false; break; }
}
printf("%s\n", passed ? "Verified!" : "Failed.");
return 0;
}Timing Kernels with KernelProfiler
Time your kernels with warmups to skip JIT delays, then average a bunch of runs. Full vector add (buffers set up as above).
#include "tinycuda/tinycuda.hpp"
#include <vector>
#include <cstdio>
#include <cmath>
int main() {
const int N = 1024;
const int threads = 256;
const int blocks = (N + threads - 1) / threads;
std::vector<float> h_a(N, 1.0f), h_b(N, 2.0f), h_out(N, 0.0f);
tinycuda::Buffer<float> buf_a(h_a.data(), N);
tinycuda::Buffer<float> buf_b(h_b.data(), N);
tinycuda::Buffer<float> buf_out(h_out.data(), N);
buf_a.to_gpu(); buf_b.to_gpu(); buf_out.to_gpu();
// Time kernel (5 warmups, 50 runs)
tinycuda::KernelProfiler prof(5, 50);
float ms = prof([&] { vector_add<<<blocks, threads>>>(buf_a.gpu_data(), buf_b.gpu_data(), buf_out.gpu_data(), N); });
buf_out.to_cpu();
// Quick check (as above)
bool passed = true;
for (int i = 0; i < N; ++i) {
if (std::abs(h_out[i] - 3.0f) > 1e-5f) { passed = false; break; }
}
printf("Avg time: %.4f ms | %s\n", ms, passed ? "Verified!" : "Failed.");
return 0;
}Catching Errors with CUDA_CHECK
Just include the header—it defines CUDA_CHECK for you. Wrap your CUDA calls to auto-check and bail on errors with a nice message. Vector add using raw calls (to demo CUDA_CHECK; Buffer hides these).
#include "tinycuda/error.hpp" // Brings in CUDA_CHECK
#include <vector>
#include <cstdio>
#include <cmath>
int main() {
const int N = 1024;
const int threads = 256;
const int blocks = (N + threads - 1) / threads;
std::vector<float> h_a(N, 1.0f), h_b(N, 2.0f), h_out(N, 0.0f);
float *d_a, *d_b, *d_out;
CUDA_CHECK(cudaMalloc(&d_a, N * sizeof(float)));
CUDA_CHECK(cudaMalloc(&d_b, N * sizeof(float)));
CUDA_CHECK(cudaMalloc(&d_out, N * sizeof(float)));
CUDA_CHECK(cudaMemcpy(d_a, h_a.data(), N * sizeof(float), cudaMemcpyHostToDevice));
CUDA_CHECK(cudaMemcpy(d_b, h_b.data(), N * sizeof(float), cudaMemcpyHostToDevice));
CUDA_CHECK(cudaMemset(d_out, 0, N * sizeof(float)));
vector_add<<<blocks, threads>>>(d_a, d_b, d_out, N);
CUDA_CHECK(cudaGetLastError());
CUDA_CHECK(cudaDeviceSynchronize());
CUDA_CHECK(cudaMemcpy(h_out.data(), d_out, N * sizeof(float), cudaMemcpyDeviceToHost));
CUDA_CHECK(cudaFree(d_a)); CUDA_CHECK(cudaFree(d_b)); CUDA_CHECK(cudaFree(d_out));
// Quick check (as above)
bool passed = true;
for (int i = 0; i < N; ++i) {
if (std::abs(h_out[i] - 3.0f) > 1e-5f) { passed = false; break; }
}
printf("%s\n", passed ? "Verified!" : "Failed.");
return 0;
}What’s Next?
Check the examples like vector_add.cu and matmul.cu in the repo for full runs with checks and timings. It fits right into bigger projects with almost no extra weight. Dive into the headers for more details!