An Enhanced RBMT: When RBMT Outperforms Modern Data-Driven Translators
Overview
Popular translation systems such as Google and Bing perform reliably for high-resource language pairs like English–French but often produce elementary errors when handling low-resource languages such as Bengali or Arabic. Although modern systems rely heavily on Neural Machine Translation (NMT)—with earlier systems using Statistical Machine Translation (SMT)—both approaches depend on large, high-quality parallel corpora. This dependency leaves many widely spoken yet low-resource languages, including Bengali, insufficiently explored in mainstream AI research.
This study aims to improve Bengali-to-English translation quality by examining rule-based, SMT-based, and NMT-based approaches individually and in various hybrid configurations. We adopt established corpus-based translators (SMT and NMT) alongside a rule-based system, then evaluate multiple integration strategies that blend rule-based and data-driven methods. Through extensive experimentation across several datasets, we identify the best-performing configuration reported to date for Bengali-to-English translation and highlight how these hybrid strategies can generalize to other low-resource languages.
Contribution
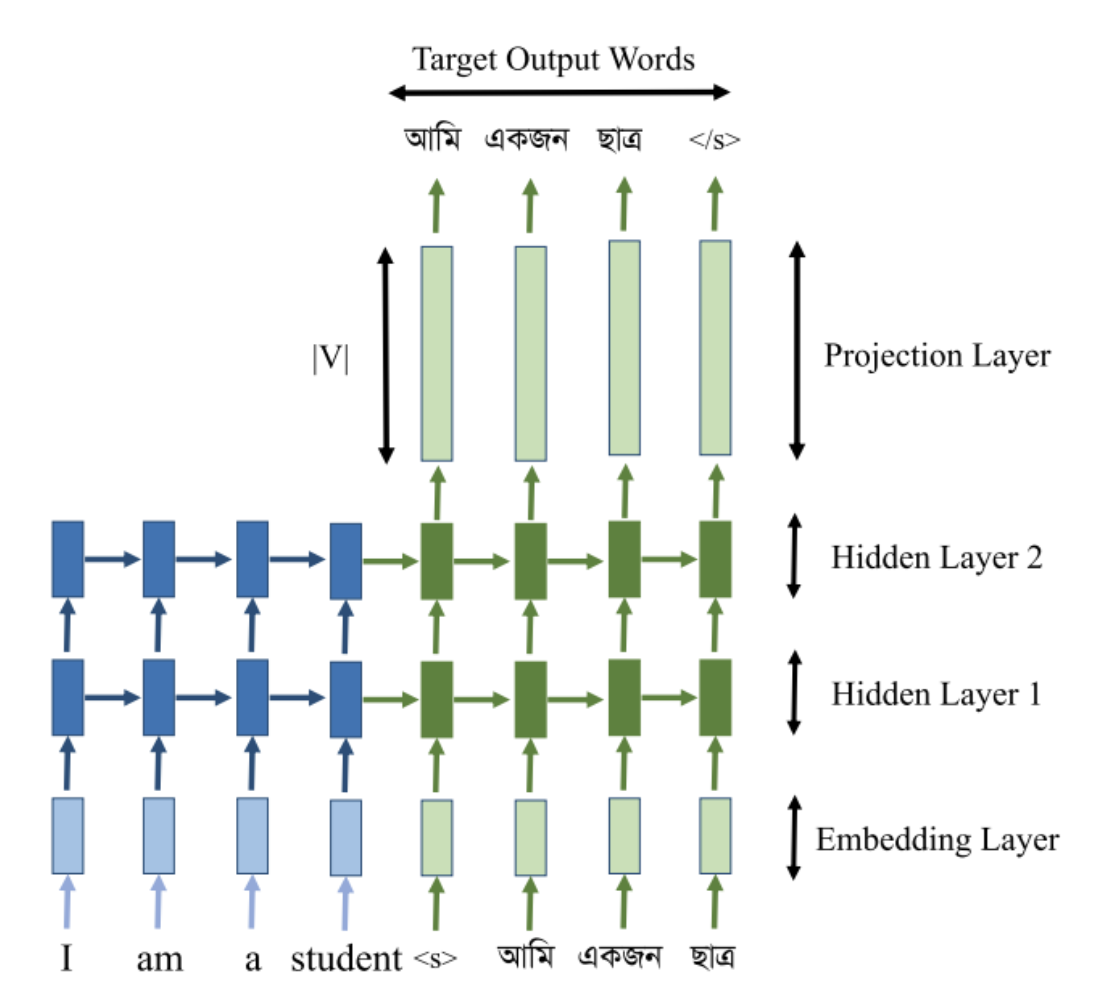
My primary contribution was the design and implementation of the RNN-based seq2seq NMT training pipeline. This included developing the end-to-end data preprocessing workflow, constructing and tuning the encoder–decoder architecture, managing the training regimen, and integrating the resulting NMT model into the broader evaluation and hybridization framework used in this study.