A Fault Tolerant Neural Machine Translation System
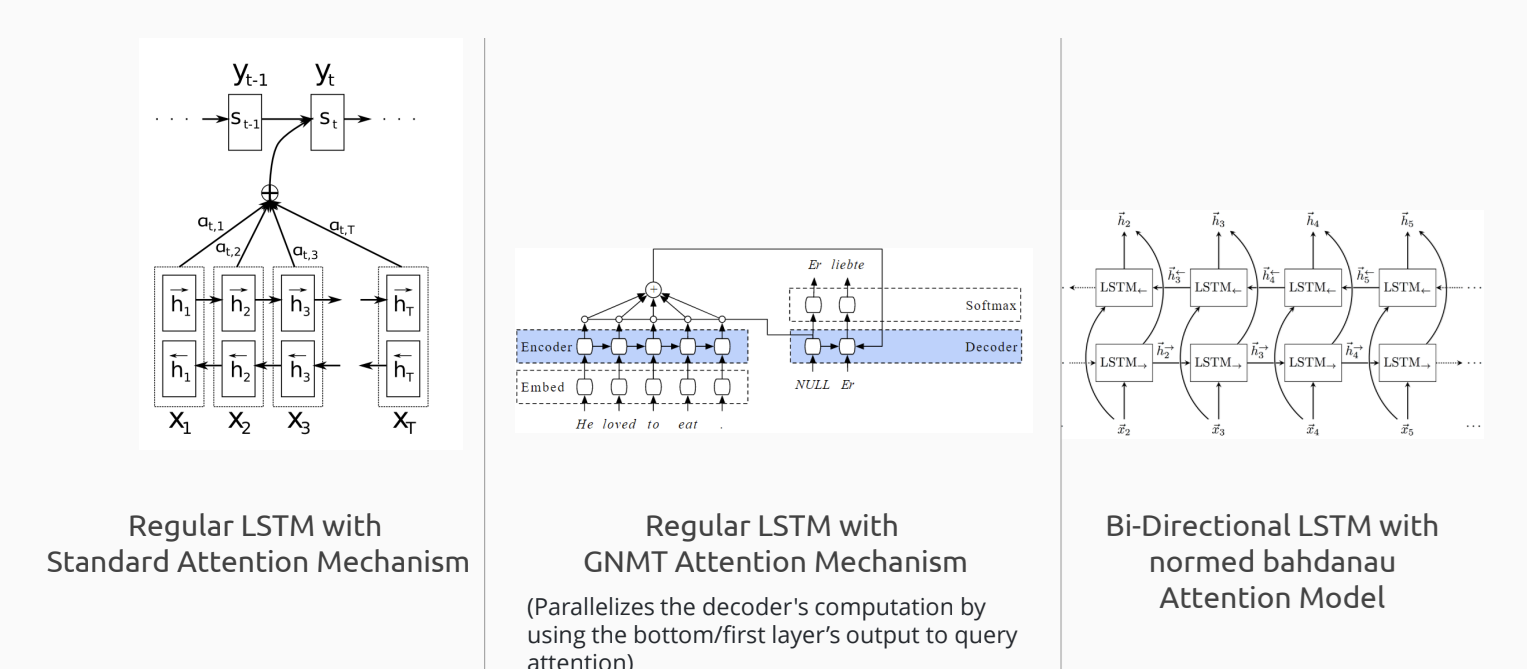
Background
Neural machine translation (NMT) systems built on sequence-to-sequence (seq2seq) architectures have become the standard for automated translation, yet individual models still struggle with linguistic ambiguity, domain shifts, and low-resource language pairs. These limitations often lead to inconsistent phrasing, mistranslations, or reduced fluency, particularly when the training data is sparse or uneven. We explored whether combining multiple translation models and strengthening the training corpus could address these challenges. By leveraging the idea that different models may capture complementary linguistic patterns, we aimed to create a system capable of generating more accurate and robust translations than any single model alone.
Methodology
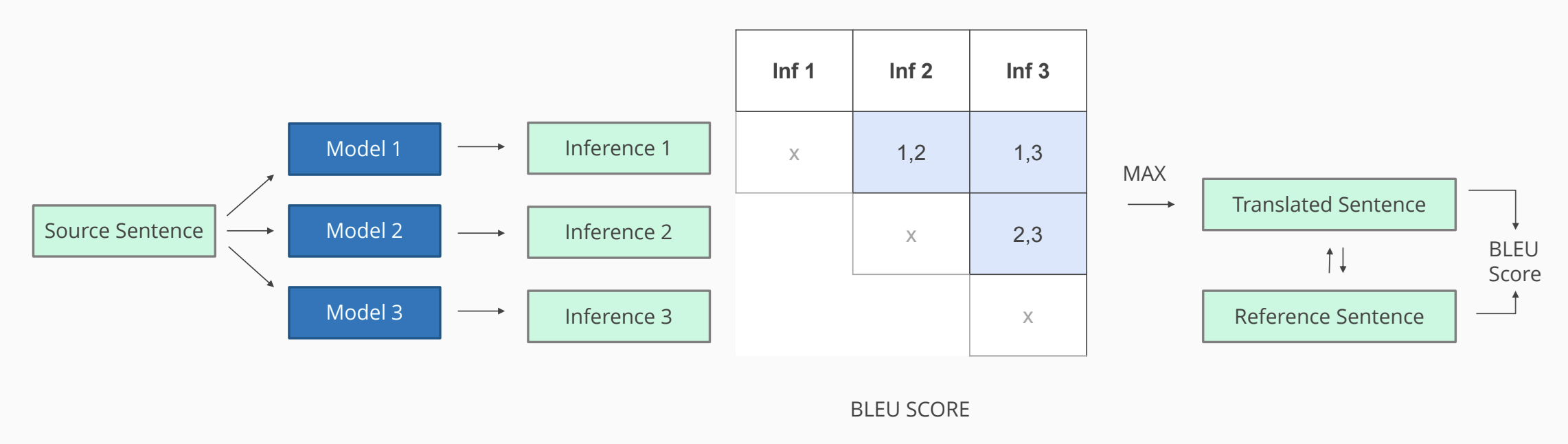
Our approach centered on two key strategies: model ensembling and dataset augmentation. For ensembling, we trained three seq2seq translation models, each on a different portion of the available training data to encourage diversity in their learned representations. Instead of traditional ensemble methods such as probability averaging or beam-level voting, we generated translations from all three models and then computed pairwise BLEU scores to assess their agreement. Using these scores, we performed a majority-voting procedure to select the final output, favoring translations that were most consistent across models.
In parallel, we augmented the dataset by partitioning it into distinct subsets for the three models, effectively exposing each model to a different slice of the overall data distribution. This form of data diversification served as a lightweight augmentation technique, increasing variability without introducing synthetic noise. We evaluated the resulting hybrid system using standard machine translation benchmarks, measuring its accuracy, fluency, and robustness across multiple test sets.
Findings
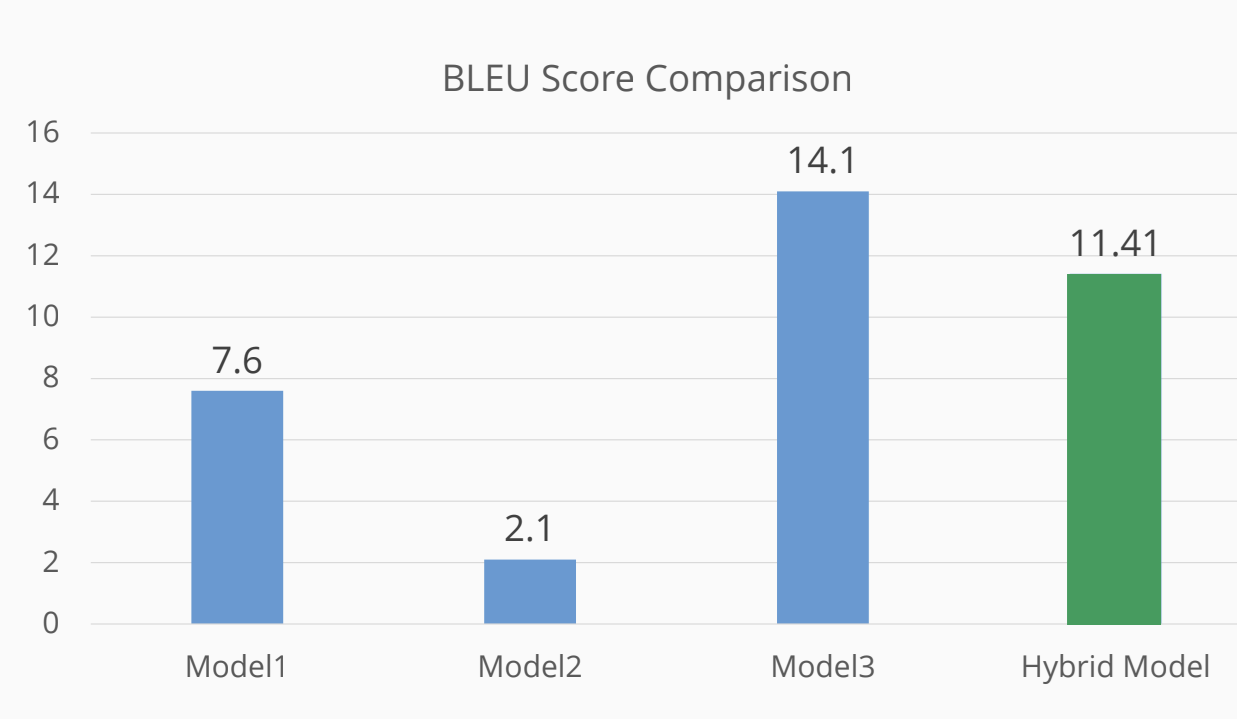
Our results showed that integrating multiple seq2seq models led to improvements over some baselines, but the hybrid method did not consistently outperform all comparison systems. While the ensemble offered modest gains in stability and occasionally reduced specific types of errors, these benefits were uneven and often dependent on the language pair or dataset. Similarly, dataset augmentation provided some boosts in generalization, but its impact varied and was sometimes offset by noise introduced during the augmentation process. Overall, we found that combining model ensembling with enriched training data has potential but did not yield uniformly superior translation quality, highlighting the need for further refinement of both the ensemble strategy and the augmentation pipeline.