An Approach Towards Multilingual Translation By Semantic-Based Verb Identification And Root Word Analysis
Background
While machine translation systems like Google Translator excel with widely spoken languages such as English, French, or Spanish, they struggle with lesser-known or newly introduced languages due to their reliance on large, high-quality datasets. Most Natural Language Processing (NLP) research has concentrated on major languages, leaving many low-resource languages underrepresented. Bengali, despite being one of the most spoken languages globally, remains a low-resource language in machine translation systems. This study addresses this gap by focusing on Bengali, aiming to improve translation quality for languages with limited representation in the field.
Methodology
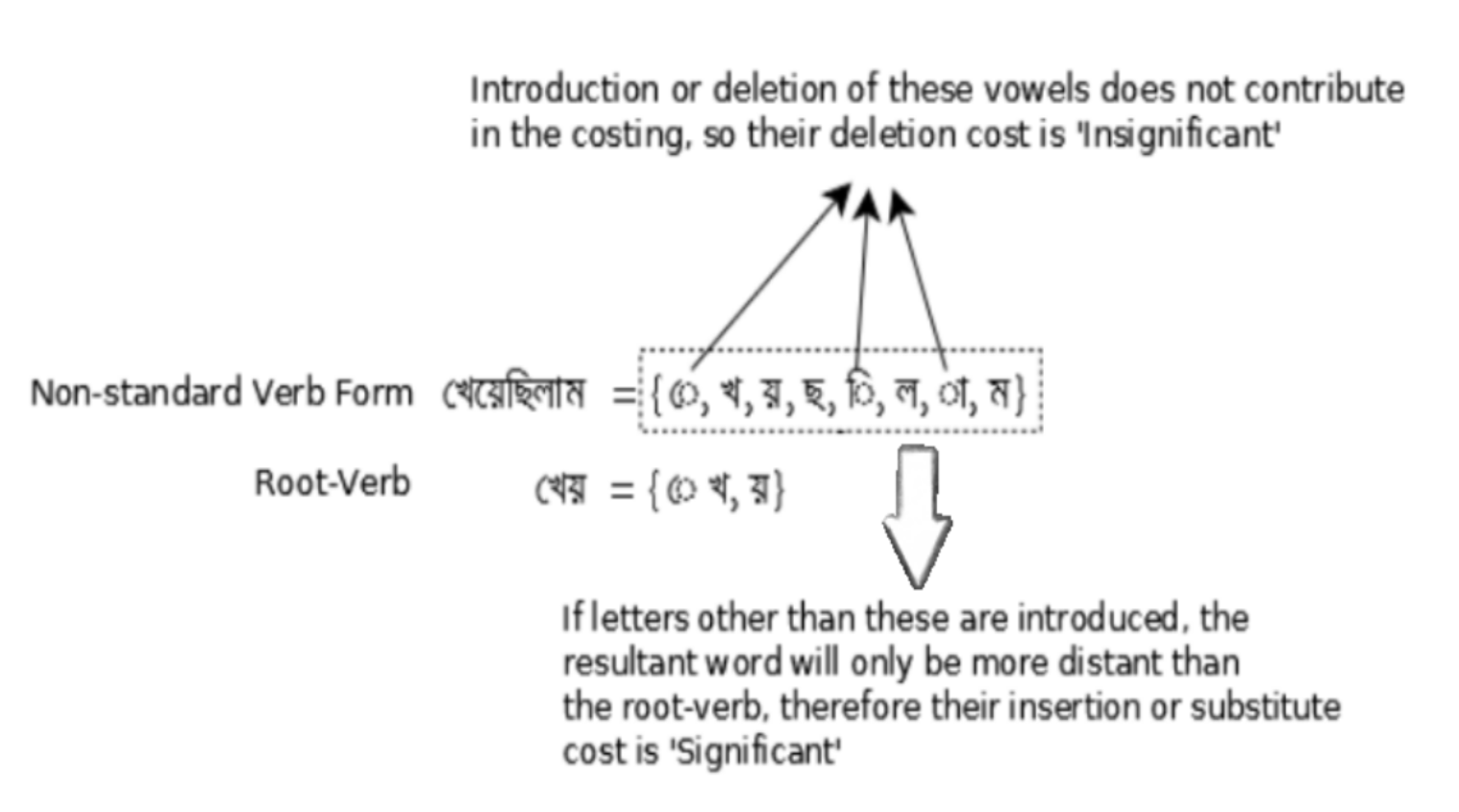
To improve Bengali translation, we propose a generalized machine translation system designed for low-resource languages. Our approach centers on two key innovations: semantic-based verb identification and root word detection. The first technique focuses on understanding verbs based on their meaning, rather than relying solely on statistical correlations, which are prone to errors. The second technique involves detecting the root form of verbs to enhance translation accuracy by capturing the verb’s core meaning in context. These strategies are intended to overcome the limitations of current statistical translation methods, improving performance with smaller datasets.
Findings
Our approach was evaluated against Google Translator in terms of accuracy, time complexity, and space complexity. The results show that the semantic-based verb identification and root word detection algorithms significantly improve the translation of Bengali verbs, outperforming Google Translator in terms of accuracy. Additionally, our method demonstrated efficient time complexity, ensuring that improvements in translation quality did not come at the expense of processing delays. The approach also maintained reasonable space complexity, allowing it to scale effectively without demanding excessive memory. Overall, our results indicate that this semantic-focused approach offers a meaningful advancement in translating low-resource languages like Bengali, balancing both accuracy and computational efficiency.