Accelerating Graph Machine Learning using Auto-tuned Sparse Primitives for GPU
Background
Sparse-dense matrix multiplication (SpMM) is a fundamental operation that underlies a wide range of scientific, machine learning, and graph-processing workloads. Its performance becomes especially critical as datasets grow larger and applications demand real-time or near–real-time computation. While existing SpMM libraries provide strong performance on CPUs, they generally lack robust support for GPU execution, particularly in areas such as auto-tuning and specialized sparse kernel optimization. This gap limits the ability of developers and researchers to fully exploit modern GPU architectures for high-throughput sparse computation.
Methodology
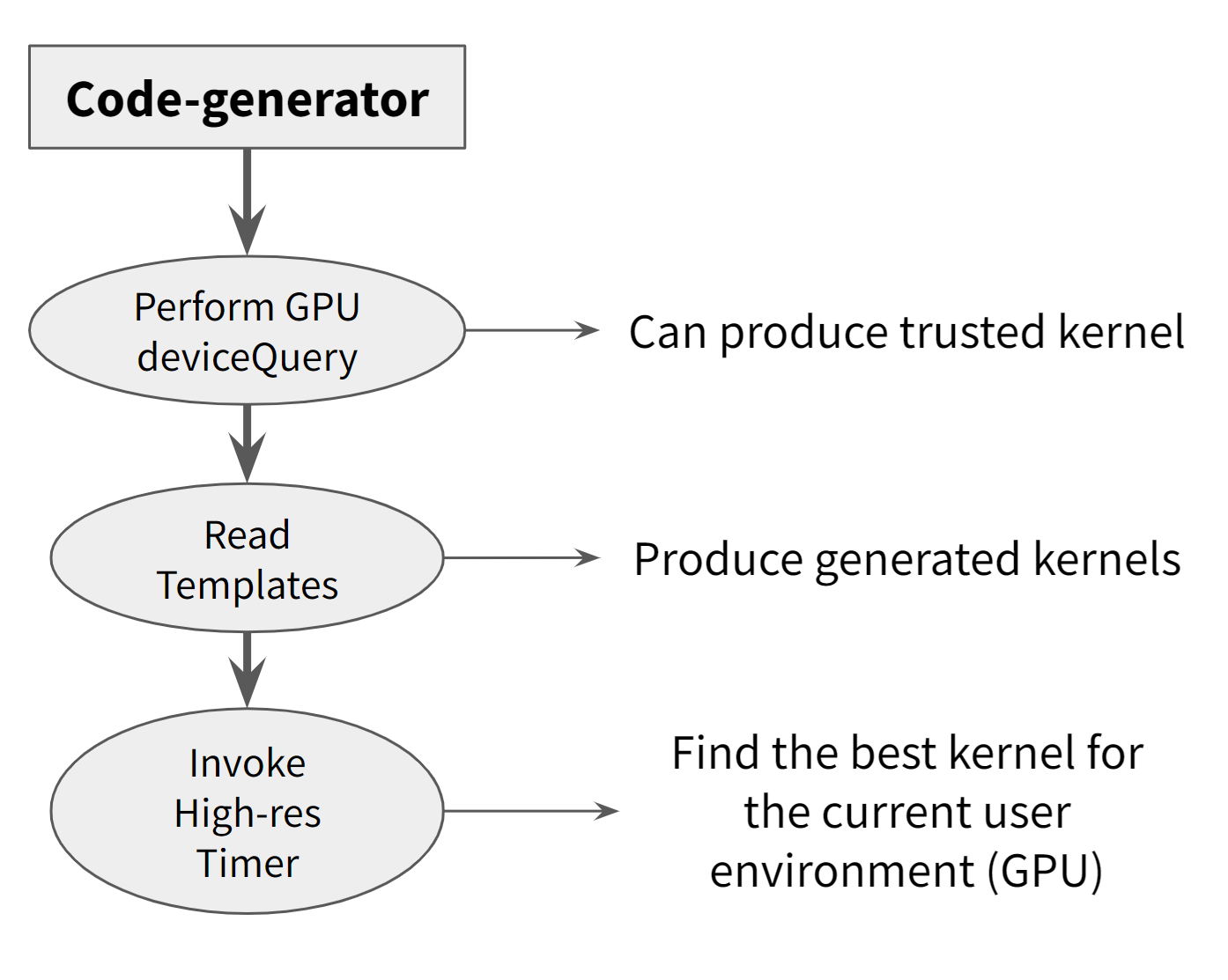
To address this limitation, we extended a generic SpMM library with a GPU-compatible auto-tuner designed to optimize sparse-dense kernel performance on contemporary GPU hardware. Our methodology involved adapting the library’s kernel-selection mechanisms to operate efficiently on GPUs, implementing GPU-specific tuning strategies, and ensuring compatibility with CUDA-based execution paths. The auto-tuner systematically benchmarks alternative kernel configurations—including thread-block layouts, memory-access patterns, and sparsity-aware execution modes—and selects the optimal configuration for a given input matrix. Throughout this process, we prioritized generality so the tuner could accommodate a wide range of sparsity patterns and workload characteristics.
Findings
The resulting GPU-enabled auto-tuner successfully expanded the library’s capabilities, allowing its sparse-dense kernels to run efficiently on modern GPU architectures. While this work represents an initial step rather than a complete overhaul of GPU-based sparse optimization, it establishes the essential infrastructure needed to explore more advanced GPU-specific techniques. By enabling auto-tuning on GPUs, the project opens a pathway for future performance improvements and broader adoption of GPU resources in applications that depend on fast and scalable SpMM operations.